LLM Evaluation: Measuring Performance
Axis Lab
This video lecture focuses on LLM evaluation, a crucial aspect of understanding and improving large language model performance. It covers methods for quantifying LLM outputs in various scenarios, including coherence, factuality, and other quality metrics.
Key highlights:
- Recap of Retrieval Augmented Generation (RAG) and tool calling.
- Discussion of the challenges in evaluating free-form LLM outputs.
- Analysis of human evaluation and inter-rater agreement.
- Introduction to agreement rate metrics and their limitations.
- Overview of automated LLM evaluation methods.
内容摘要
核心要点
- 1Evaluating LLM performance is crucial for identifying areas of improvement, focusing on output quality metrics like coherence and factuality.
- 2Human ratings are valuable but costly and subjective; inter-rater agreement metrics help ensure consistent evaluations.
- 3Rule-based metrics like METEOR and BLEU offer automated evaluation but have limitations in capturing stylistic variations and correlating with human judgment.
- 4LLM-as-a-Judge leverages LLMs to rate responses, providing scores and rationales, offering interpretability and eliminating the need for initial human ratings.
- 5Structured output techniques, such as constraints-guided decoding, can ensure LLM-as-a-Judge responses adhere to a specific format, like JSON.
- 6LLM-as-a-Judge is susceptible to biases like position, verbosity, and self-enhancement; mitigation strategies include position swapping and careful prompt engineering.
- 7Employing a larger, more capable LLM as the judge can enhance evaluation accuracy and reduce the risk of biases, ensuring better alignment with human preferences.
演示预览
幻灯片内容

This lecture focuses on LLM evaluation, emphasizing its importance for identifying areas of improvement. The core idea is that without effective performance measurement, targeted enhancements are impossible. The session will cover methods to quantify LLM performance across various scenarios, providing a foundation for optimizing LLM behavior and output quality.

Last week's lecture covered how LLMs interact with external systems, focusing on Retrieval-Augmented Generation (RAG) and tool calling. RAG involves fetching information from external knowledge bases using bi-encoders (e.g., Sentence-BERT) for candidate retrieval and cross-encoders for reranking. Tool calling enables LLMs to use external tools based on input queries. Agentic workflows combine RAG and tool calling for complex tasks like AI-assisted coding, often using the ReAct framework.
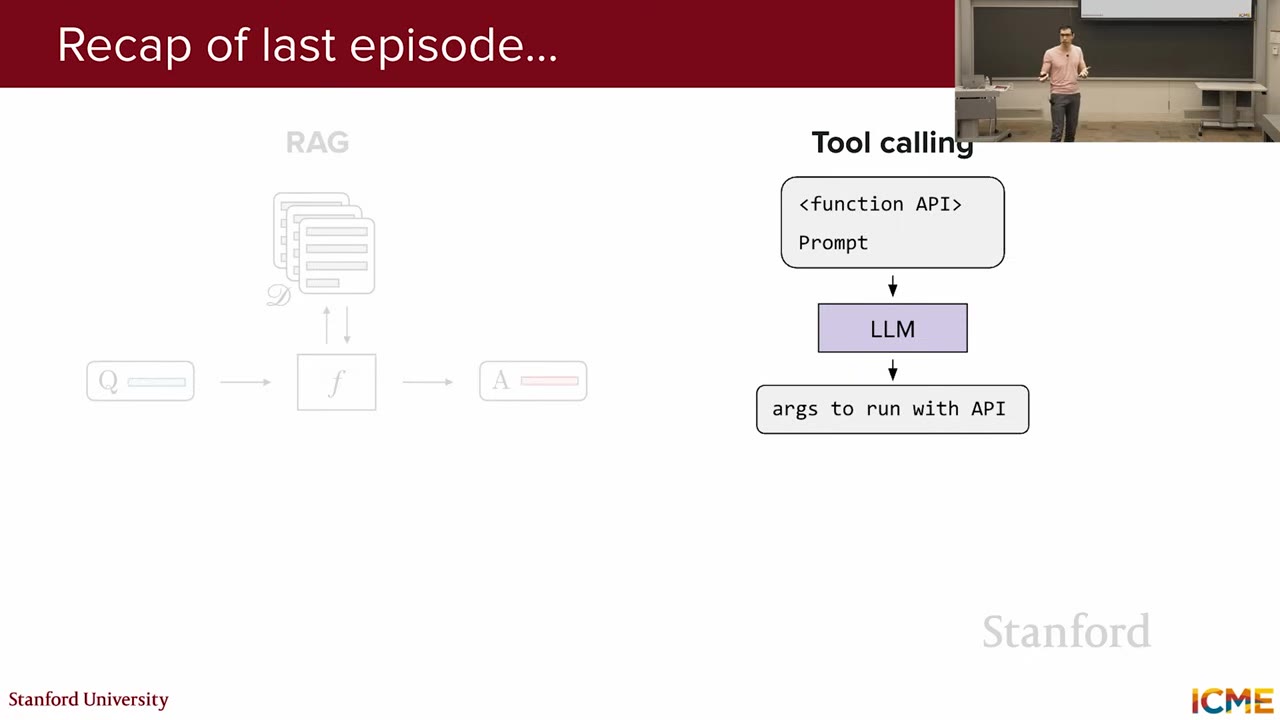
LLMs possess strengths in reasoning and knowledge retrieval but also have weaknesses that need mitigation. Lectures 6 and 7 focused on improving reasoning and knowledge access. This lecture shifts focus to evaluation, specifically quantifying the quality of LLM responses. The goal is to determine how well an LLM performs in generating appropriate and accurate outputs.

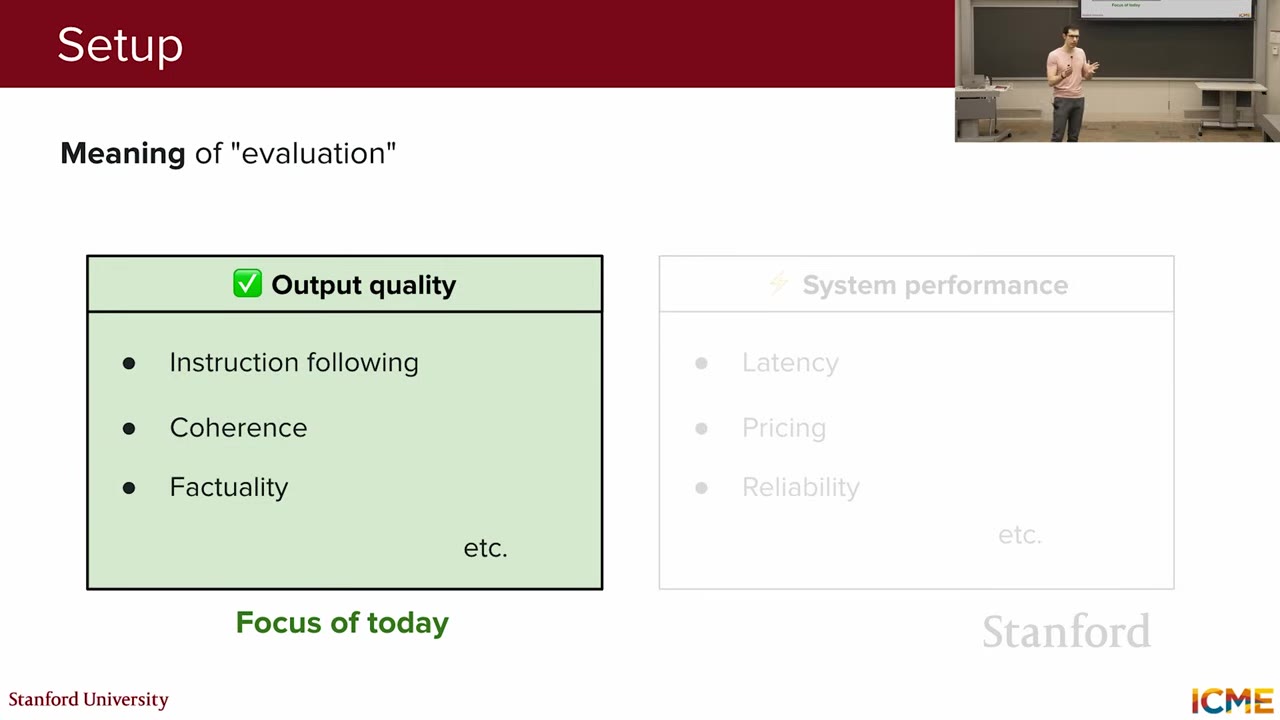
The term "evaluation" can have multiple meanings when applied to LLMs. It can refer to performance, output quality (coherence, factuality), system-level metrics (latency, pricing), or uptime. This lecture primarily focuses on output quality, specifically quantifying the goodness of LLM responses. This is a challenging problem due to the free-form nature of LLM outputs, which can include natural language, code, and mathematical reasoning.
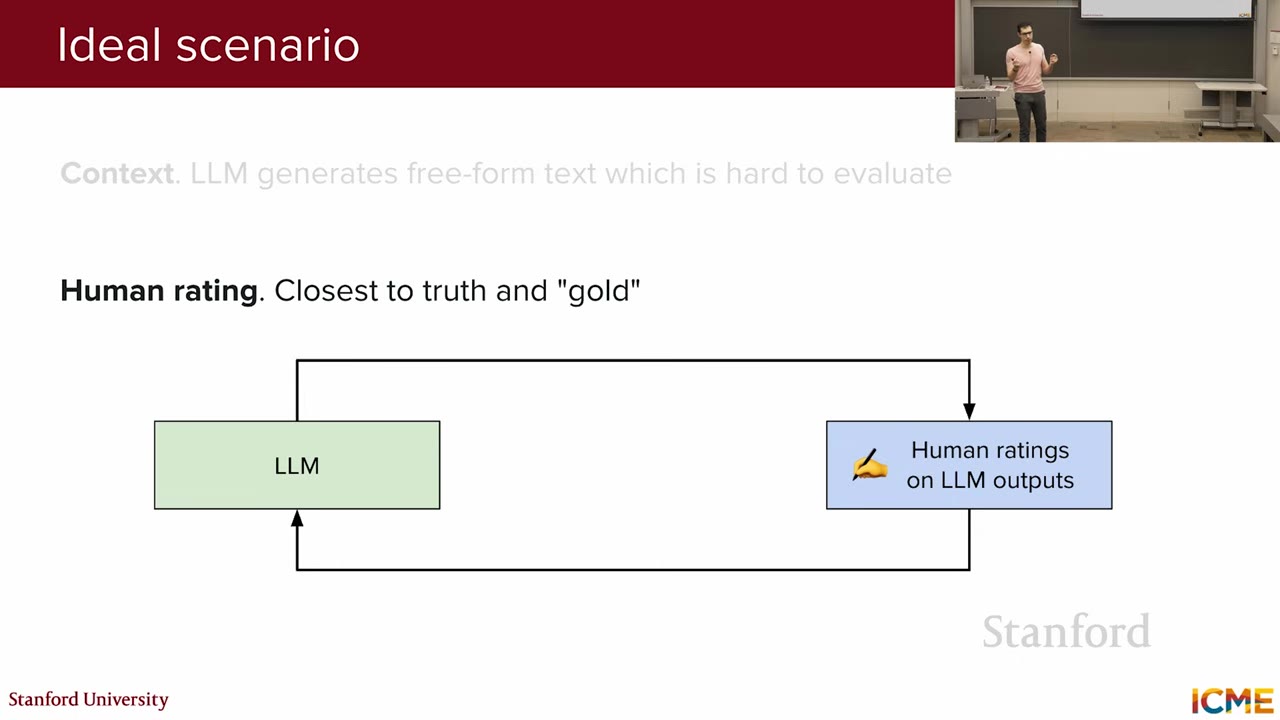
Ideally, LLM output evaluation would involve human ratings for every response. This would entail providing a prompt to the LLM, receiving a response, and then having a human rate the response. This process would be repeated to collect a comprehensive set of human evaluations to quantify overall model performance. However, this approach is highly cost-intensive and impractical for large-scale evaluations.
LLM outputs are free-form, and human judgments can be subjective. For example, evaluating the usefulness of a gift suggestion can vary based on individual perspectives. This subjectivity raises concerns about inter-rater agreement, necessitating clear guidelines to ensure consistent ratings. Agreement metrics are used to quantify the level of consistency among raters.





