GPT-5, Healthcare AI & Model Selection
Axis Lab
This video discusses the launch of GPT-5 and its implications for healthcare AI. It explores the nuances of the new model, its accuracy, and how it compares to previous versions. The conversation also covers specialized models and model selection.
- First impressions of GPT-5 and its capabilities.
- The role of reasoning models in AI.
- Benchmarks and their limitations in healthcare.
- The importance of model selection and specialized models.
- Challenges in evaluating AI system performance.
内容摘要
核心要点
- 1The latest LLMs, while impressive, still require careful integration into healthcare workflows to ensure consistent and high-quality outputs.
- 2Model selection is crucial; specialized models tailored to healthcare data and tasks may outperform general-purpose LLMs in specific applications.
- 3Successful AI implementation requires a deep understanding of clinical needs and workflows, emphasizing the importance of domain expertise.
- 4Focus on building robust pipelines, monitoring systems, and feedback loops to continuously improve AI-driven healthcare solutions.
- 5User experience design must consider the balance between immediate responses and the potential benefits of longer processing times for more complex tasks.
- 6AI should augment, not replace, human expertise, requiring careful consideration of how to maintain essential clinical skills.
- 7Integrated systems that connect patients and care teams, grounded in comprehensive medical records, offer the greatest potential for improving healthcare outcomes.
演示预览
幻灯片内容
The discussion begins with an overview of GPT-5 and its performance on various benchmarks, including those relevant to healthcare. The conversation explores the nuances of model evaluation and the need for benchmarks that reflect real-world clinical scenarios.
The panel discusses the importance of model selection, highlighting the emergence of specialized models tailored for specific tasks. This includes models designed for image analysis and other modalities beyond natural language processing.
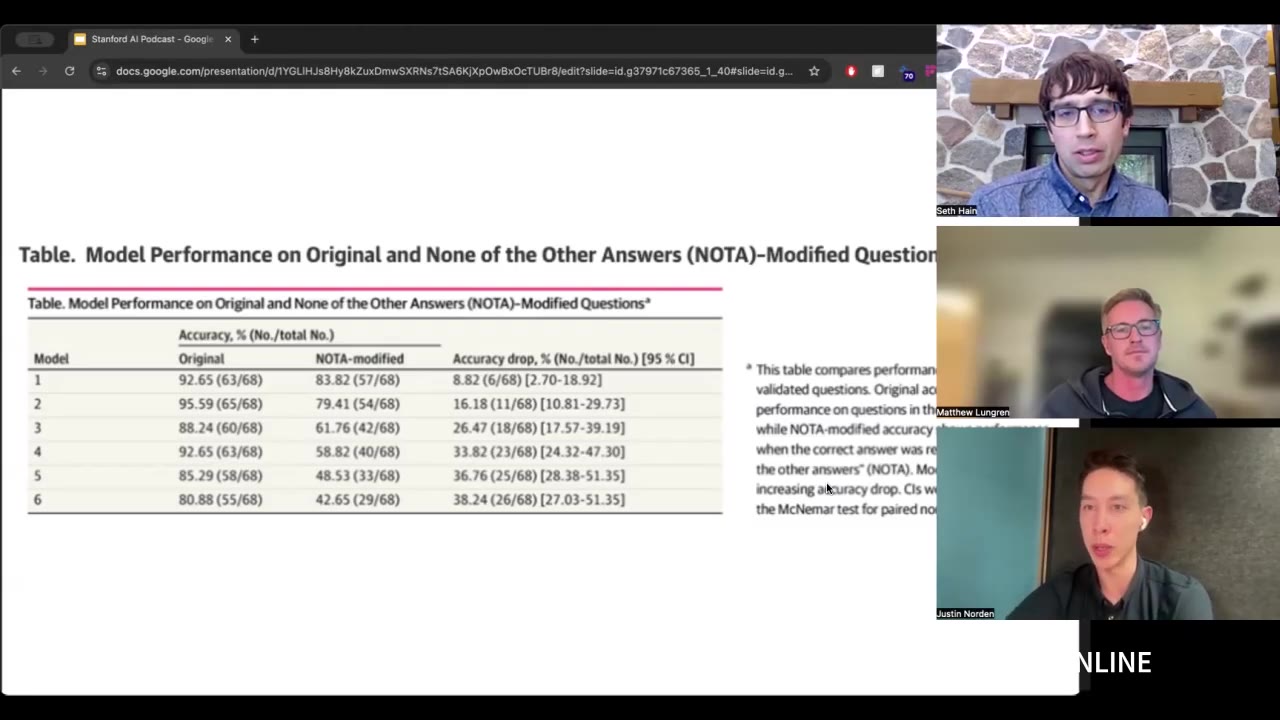
The limitations of relying solely on multiple-choice questions as benchmarks are examined. The non-deterministic nature of LLMs and the need for consistent responses are also discussed.
The conversation addresses the challenges of translating AI research into practical healthcare applications. The importance of considering the context of use and incorporating checks and balances into AI-driven solutions is emphasized.
The discussion highlights the importance of asking meaningful questions and understanding the problems faced by clinicians. The need for developers to spend time in clinical settings to gain insights into real-world needs is emphasized.
The panel explores the evolving user experience patterns for AI in healthcare, particularly in situations where longer processing times can lead to improved outcomes. The need for a thoughtful conversation about the trade-offs between speed and accuracy is highlighted.





