Large Language Models (LLMs) Explained
Axis Lab
This video introduces Large Language Models (LLMs), exploring their architecture, training, and key characteristics. Learn about the different types of LLMs, including decoder-only models, and the concept of Mixture of Experts (MoE).
Key highlights:
- LLM definition and characteristics: size, data, compute.
- Decoder-only architecture and its prevalence in modern LLMs.
- Introduction to Mixture of Experts (MoE) and its benefits.
- Examples of popular LLMs like GPT, Llama, and Gemma.
概要
重要ポイント
- 1LLMs are characterized by their large size, extensive training data, and significant computational requirements, distinguishing them from smaller language models.
- 2Modern LLMs predominantly use a decoder-only architecture, leveraging masked self-attention and feedforward neural networks for text generation.
- 3Mixture of Experts (MoE) enhances LLM efficiency by activating only a subset of parameters during inference, reducing computational costs.
- 4Sparse MoEs select a limited number of top experts for computation, further optimizing resource utilization and FLOPS.
- 5Routing collapse, where only a few experts are consistently activated, is a challenge in MoE training, mitigated by modified loss functions.
- 6Decoding strategies like maximum probability selection offer simplicity but lack diversity, while beam search aims for global optimality at the cost of increased computation.
- 7Beam search maintains multiple probable paths during decoding, using a length normalization term to counteract the bias towards shorter sequences.
ウォークスルー
スライド内容

Slides are available on the website before class for annotation. Slides will be published every Thursday evening.
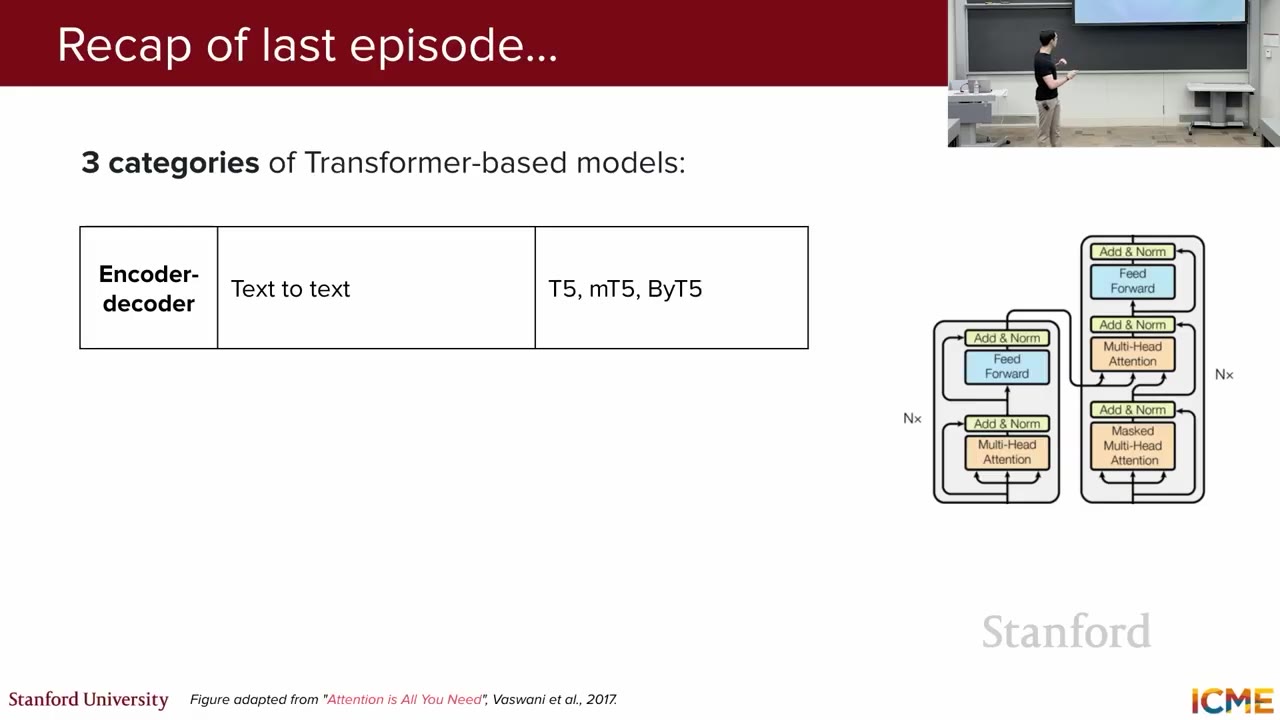
Lecture 1 and 2 introduced self-attention and transformers. Last lecture covered model types based on the transformer architecture: encoder-decoder (e.g., T5), encoder-only (e.g., BERT), and decoder-only (e.g., GPT). BERT's embeddings are meaningful and expressive, useful for tasks like classification and sentiment extraction.

Encoder-decoder models (text-in, text-out) use both encoder and decoder transformers. Encoder-only models (e.g., BERT) provide meaningful embeddings. Decoder-only models (text-in, text-out) like GPT are now the most common type of LLM.
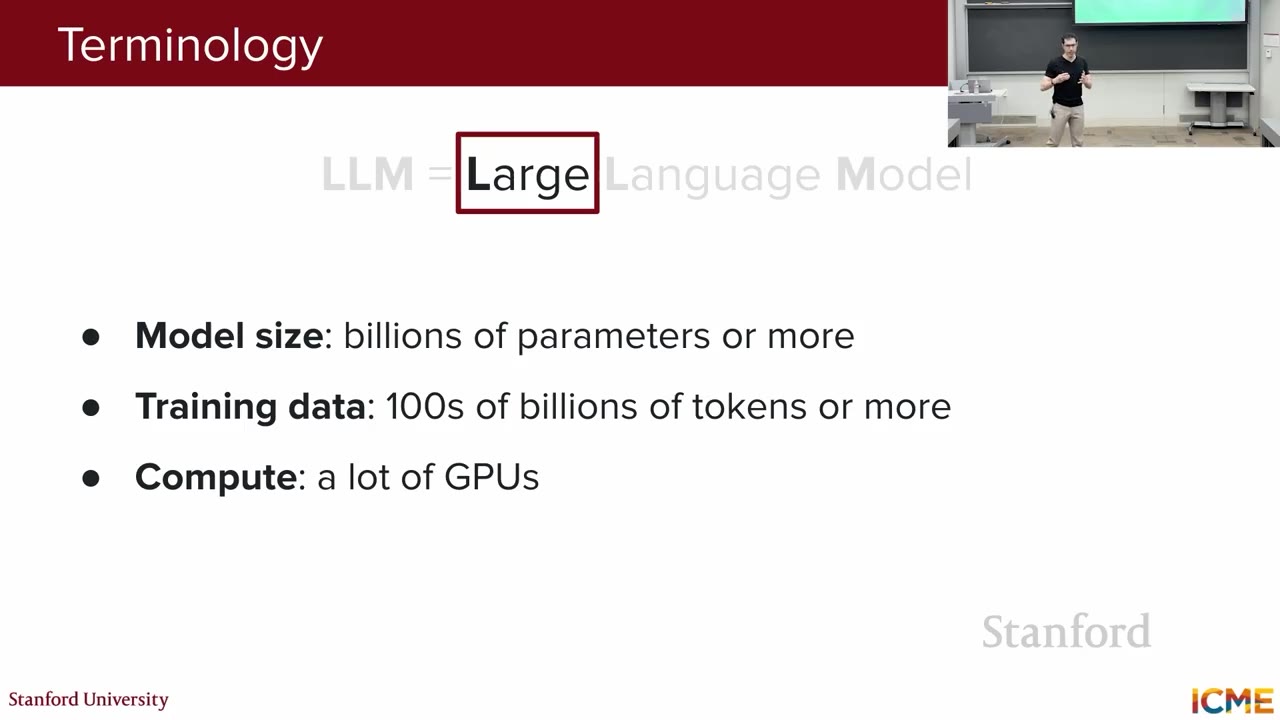
LLM stands for Large Language Model. A language model assigns probabilities to token sequences, predicting the next token. LLMs are large in model size (at least billions of parameters), training data (hundreds of billions to trillions of tokens), and compute requirements (multiple GPUs).

The term LLM is relatively new. Current definition includes text-to-text models that are large in size, data, and compute. These models are decoder-only, removing the encoder and keeping masked self-attention, feedforward neural network, addition, and normalization.

Examples of decoder-only LLMs include LLaMA, Gemma, DeepSeek, Mistral, and Qwen. Over 90% of modern LLMs are decoder-only. These models are large, requiring significant compute for training and inference.





